Introducción
Tras muchas semanas de retraso debido a una serie de contratiempos ¡Por fin tenemos la segunda parte de este tema!He encontrado varios problemas para publicar este artículo:
- La gripe, tres días en cama no ayudan a escribir esto.
-
Github desktop no está funcionando en
mi laptop. Esto es un problema porque quería intentar hacer un repositorio útil
para este artículo, en cambio sigo usando Github de manera pedestre. Bueno,
poco a poco.
-
Mi obsesión por que los script se puedan ejecutar copiando y pegando. Odio
cuando alguien cuelga un script que no funciona. (Igual dentro de unos
meses este script deja de funcionar. Si eso pasase avísadme)
Una vez más me gustaría agradecer a Álex Estudillo por los datos proporcionados (medias y desviaciones) y las imágenes.
Los datos los he generado basándome en unos datos de Alex tomando medias y desviaciones. Luego he simulado la matriz por sujetos con distribuciones normales.
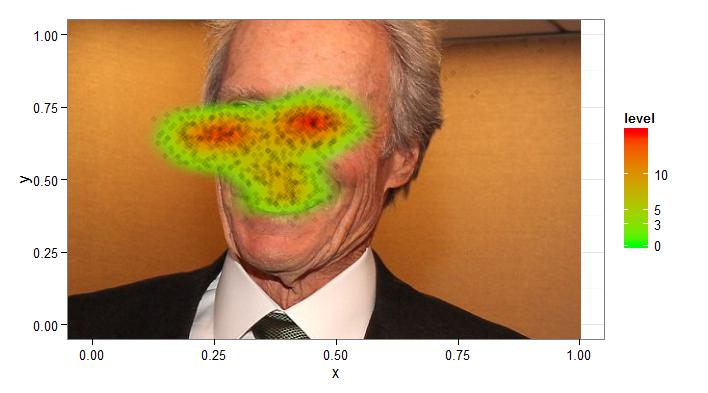
La imagen sobre la que trabajaremos es la siguiente. Que por cierto, es propiedad intelectual de Álex, así que está aquí solo con fines de reproducción del ejemplo. Aun así por si acaso he modificado la imagen con GIMP.

Tratamiento de datos y descarga
Solución 1
La primera solución es muy parecida a lo que hice en el post anterior, lo único que aportacoord_fixed() es que nos fija las imágenes para que no tengamos problemas con el reescalamiento.
Las órdenes de dibujo que definen el objeto ggplot vienen de la librería ggplot2.

Solución 2
Aquí solo aporto una función para controlar los colores del heatmap, función que será utilizada durante todo el resto del ejercicio al quedar los colores bastante más aparentes. Ver lineas: 3 y 23.colorRamp viene de la librería grDevices

Solución 3
Los heatmaps con distribuciones están muy bien de cara a
representar, pero lo que buscamos es mas bien un histograma sobre el plano que
nos cuente el número de ocurrencias por punto. Para este fin podemos
definir zonas de interés mediante hexágonos y de esta manera generamos el
heatmap-histograma. Lo malo de esta solución es que es difícil generar
los hexágonos de manera que queden exactamente en las ROIs que queremos y por
tanto es una solución poco útil de cara al análisis.
stat_binhex nos permite crear tantos hexágonos como queramos
para definir ROIs. El parámetro de bins nos da el número de hexágonos que caben
en el eje x.

Como veis el resultado es muy similar, pero ahora ya hemos
definido algo aproximado a una zona de interés.
Solución 4
Ahora vamos a definir unas zonas de interés con cuadrados.
Es la misma lógica que tienen los hexágonos sólo que los cuadrados tendrán mucho
más juego al poderse elegir más fácilmente donde los colocamos.
stat_bin2d La orden utilizada será ésta y tiene un uso similar a la que tiene la orden stat_binhex, aunque como veremos en el último apartado es mucho más flexible.

Solución 5
Esta solución consiste en crear la matriz de frecuencias a mano y representárla con la orden surface3d del paquete rgl. Lo bueno de esta solución es que ya tenemos la matriz de
frecuencias lista para el análisis y que además nos da un dibujo en 3D que se
puede mover. Esta solución es bonita
pero poco útil.
Solución 6
Basándonos en la matriz de frecuencias de la solución 5
podemos intentar hacer otro tipo de dibujo. Sólo que ahora aproximaremos por polinomios a una forma que se ajuste a los valores dados. El heatnap queda aparente y nos da una visión más general de a dónde han ido las miradas, pero no nos permite hacer un análisis lo suficientemente bueno.

Analisis final
Ahora vamos a utilizar la solución 4, que es la que más me gustó, para terminar el análisis. Pero vamos a elegir las ROI de manera manual y no de manera automática. Para ello definiremos los cuadrados con unos vectores para generar las distintos ROIs.stat_bin2d(breaks = list( x= seq(from = 0, to = 1000, by = 50),
y = seq(from = 0, to = 800, by = 50) )

Por último analizaremos las frecuencias con un test de proporciones. Los pasos son los siguientes:
- Lo primero con ggplot_build hemos sacado la estructura de la matriz que genera el plot. Mucho más sencillo que como lo hemos hecho en las soluciones 5 y 6 (línea4)
- Luego nos hemos fijado en los cuadrantes donde los sujetos se fijaron más de 500 veces.
- Se observa el cuadrante (250,300] (350,400] Ojo izquierdo de la cara izquierda (línea 10)
- También podemos ver el cuadrante (700,750] (350,400] que es el ojo derecho de la cara de la derecha. Ambos cuadrantes son los más calientes.
-
Por último vamos a comparar si los sujetos en general se han fijado más en un cuadrante o en el otro. Para ello hacemos un test de proporciones en el que nos da un p valor menor que 0.05 (línea 24), con lo que podemos concluir que efectivamente se han fijado más en un cuadrante que en otro.
Reflexiones
- No me termina de hacer chiste cómo están representados los datos. Ese ajuste que tuve que hacer en la solución uno (líneas 10 y 11 de la solución 1) y que he arrastrado todo el post me hace sospechar que algo no del todo bueno a pasado entre los datos y la representación.
- Por si acaso advierto que en un estudio real no miraríamos lo que he mirado. En un análisis haríamos comparaciones entre cuadrante y sujetos (grupos, condiciones) con un glm y así ver qué diferencias ha habido según una hipótesis.
- Los cuadrantes han de ser definidos con cuidado para definir las áreas de interés en zonas claves según la literatura. Aún así, como definimos los cuadrantes de manera manual, siempre tiene un punto arbitrario y peligroso. Mi recomendación es definir las ROIs antes de hacer los análisis para evitar sesgos o tentaciones.
- Tengo total desconocimiento sobre las ROIs en este tipo de estudios y por tanto cualquier análisis más complejo que hiciese no podría ser tomado en serio.
- Todo esto ha costado de hacer, pero estoy bastante contento con los resultados. Espero que la currada haya merecido la espera. Gracias por seguirme.
Bibliografía




{kind=link}